※ 네이버 지식백과
※ 나무위키, 위키백과
※ TTA 용어사전
※ 구글링
NLP 기초 다룬 뒤에, 챗봇 개념 다루면 될 듯
[목차]
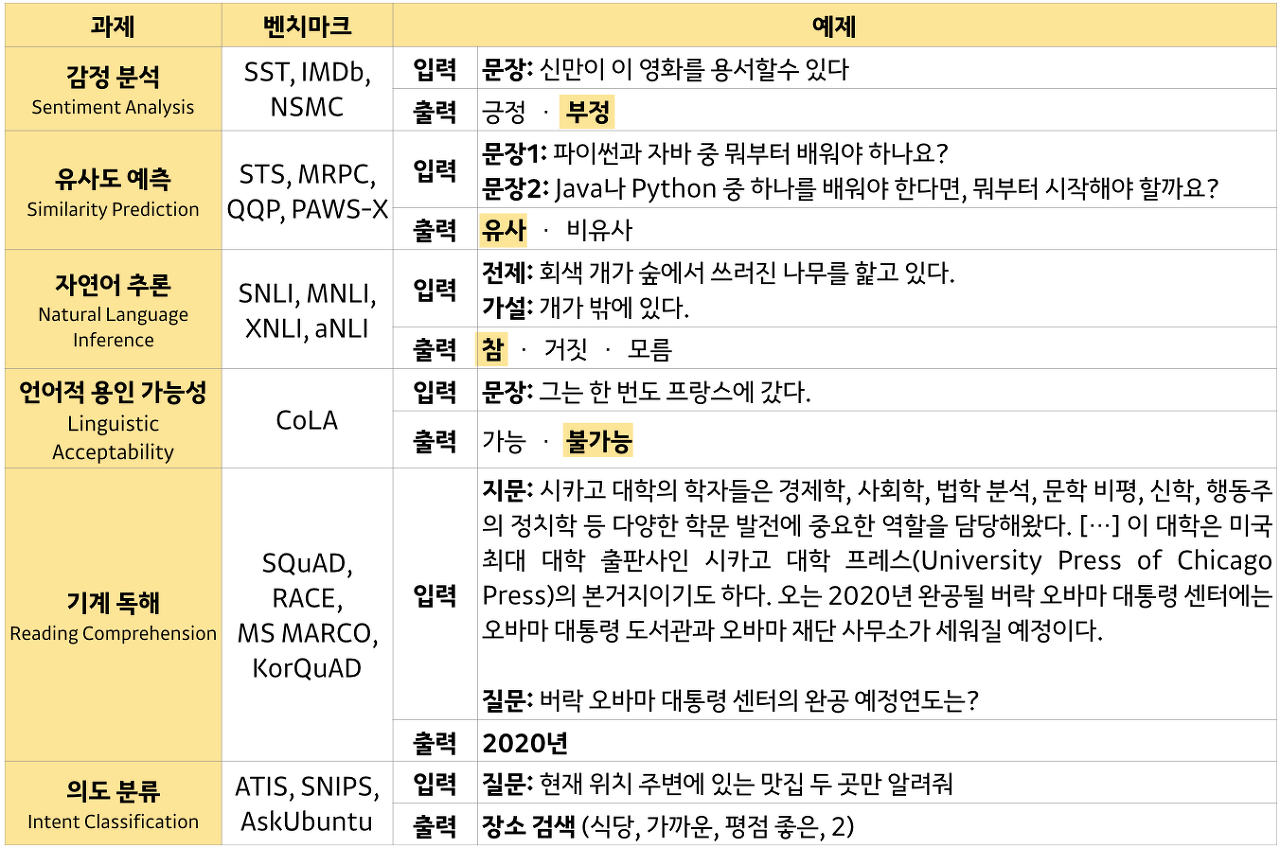
자연어란
자연어 처리란
자연어 처리에 사용되는 기술
- 자연어 분석
- 자연어 이해
- 자연어 생성
자연어 분석
- 형태소 분석
- 통사 분석(구문 분석)
- 의미 분석
- 화용 분석
자연어 이해
- 자연어 이해란
- 전통적 방식(룰 기반 또는 머신러닝 기반)의 한계
- 딥러닝 방식의 개선
- NLU를 사용하는 기술
- 다양한 언어 모델
자연어 생성
- 자연어 생성이란
- 언어 모델이란
- 언어 모델이 하는 일
- 최신 언어 모델
챗봇이란
챗봇의 5가지 대표 유형/종류
- 대화형 챗봇
- 트리형(버튼) 챗봇
- 추천형 챗봇
- 시나리오형 챗봇
- 결합형 챗봇
NLP와 챗봇의 관계
자연어 처리 엔진과 챗봇 빌더
- 자연어 처리 엔진
- 챗봇 빌더란
- 챗봇 빌더의 종류
챗봇 주요 용어
- 인텐트(Intent, 의도)
- 말문장(Utterance)
- 엔티티(Entity)
- 시나리오(Senario)
- 슬롯 채우기(Slot Filling)
- 스몰토크(Smalltalk)
□ 자연어(Natural Language)란
참조: https://terms.naver.com/alikeMeaning.nhn?query=00057840
■ 컴퓨터에서 사용하는 프로그램 작성 언어 또는 기계어와 구분하기 위해 인간이 일상생활에서 의사 소통을 위해 사용하는 언어를 가리키는 말. 컴퓨터 환경에서 자연 언어를 이해하고 모방하는 것이 인공 지능 분야의 연구 목표 중 하나이다.
[네이버 지식백과] 자연어 [natural language, 自然語] (IT용어사전, 한국정보통신기술협회)
■ 자연언어는 인공언어와 대치되는 개념이다. 한국어, 프랑스어, 영어, 러시아어 등의 자연언어는 인류라고 하는 종(種) 전체에 나타나는 특유한 것이다. 커뮤니케이션과 표현의 도구인 자연언어는, 모든 인간의 언어 활동에 보편적인 특징으로 의거하고 있다.
[네이버 지식백과] 자연언어 [natural language, 自然言語] (두산백과)
■ 한국어나 영어와 같이 인간이 일상 사용하고 있는 언어. 컴퓨터에서 사용하는 언어는 보통 인공 언어(artificial language)라고 하며 사용 방법이나 쓰는 방법 등이 매우 자세히 정해져 있다. 이것은 컴퓨터가 참(true)인가 거짓(false)인가 하는 두 개의 상태밖에 표현하지 않는 논리 회로(logic circuit)로 구성되어 있는 데 기인한다. 이것에 대하여 자연 언어는 애매함이나 그때마다 여러 가지 생략이나 환언함이 있다. 더욱이 사회적인 지식 등도 필요하기 때문에 컴퓨터가 이해하는 것은 매우 곤란하다. 컴퓨터를 사용하여 이와 같은 자연 언어를 처리하는 것을 자연 언어 처리라고 하며, 1950년대부터 이와 같은 연구가 행해지고 있다. 이미 보조적으로 사용 될 수 있는 기계 번역 등의 프로그램이 만들어져 있으나, 특정 분야에 한정되어 있는 것이 대부분이다.
[네이버 지식백과] 자연 언어 [natural language] (컴퓨터인터넷IT용어대사전, 2011. 1. 20., 전산용어사전편찬위원회)
■ 자연 언어(또는 자연어, Natural Language)란 프로그래밍 언어와 같이 사람이 인공적으로 만든 언어가 아닌, 사람이 일상생활과 의사소통에 사용해 온, 한국어, 영어와 같이 오랜 세월에 걸쳐 자연적으로 만들어진 언어라는 의미로, 우리가 흔히 말하는 언어를 뜻한다.
언어 - 나무위키
분절성: 언어는 연속적인 것으로 이루어진 세계를 불연속적인 것으로 끊어서 표현한다. 예를 들어 무지개 색의 경우 우리는 7가지 색(빨, 주, 노, 초, 파, 남, 보)으로 나누어서 생각하지만 실제로
namu.wiki
□ 자연어 처리(Natural Language Processing, NLP)란
■ 컴퓨터를 이용해 사람의 자연어를 분석하고 처리하는 기술. 요소 기술로 자연어 분석, 이해, 생성 등이 있으며, 정보 검색, 기계 번역, 질의응답 등 다양한 분야에 응용된다.
자연어는 일반 사회에서 자연히 발생하여 사람이 의사소통에 사용하는 언어로, 컴퓨터에서 사용하는 프로그래밍 언어와 같이 사람이 의도적으로 만든 인공어(constructed language)에 대비되는 개념이다.
자연어 처리에는 자연어 분석, 자연어 이해, 자연어 생성 등의 기술이 사용된다. 자연어 분석은 그 정도에 따라 형태소 분석(morphological analysis), 통사 분석(syntactic analysis), 의미 분석(semantic analysis) 및 화용 분석(pragmatic analysis)의 4 가지로 나눌 수 있다. 자연어 이해는 컴퓨터가 자연어로 주어진 입력에 따라 동작하게 하는 기술이며, 자연어 생성은 동영상이나 표의 내용 등을 사람이 이해할 수 있는 자연어로 변환하는 기술이다.
자연어 처리는 인공 지능의 주요 분야 중 하나로, 1950년대부터 기계 번역과 같은 자연어 처리 기술이 연구되기 시작했다. 1990년대 이후에는 대량의 말뭉치(corpus) 데이터를 활용하는 기계 학습 기반 및 통계적 자연어 처리 기법이 주류가 되었으며, 최근에는 심층 기계 학습(deep learning) 기술이 기계 번역 및 자연어 생성 등에 적용되고 있다.
[네이버 지식백과] 자연어 처리 [Natural Language Processing, 自然語處理] (IT용어사전, 한국정보통신기술협회)
■ 인간의 언어를 컴퓨터에 인식시키는 기술.
챗봇을 활용한 질의 응답 번역 등에 활용된다.
`자연어 처리’ 기술은 사용자가 많은 영어와 중국어를 기반으로 발전했기 때문에 영어나 중국어 챗봇들은 한국어 챗봇보다 대화가 자연스럽다.
MS가 중국에서 선보인 ‘샤오아이스’는 일상적인 대화를 50문장 이상 이어갈 수 있다. 미국 젊은 소비자를 고객층으로 확보하고 있는 메신저 업체 킥은 화장품·의류 업체들과 연계한 ‘봇숍’으로 인기를 끌고 있다. 코디네이터처럼 사용자와 대화하며 취향에 맞는 옷과 화장품을 골라준다.
[네이버 지식백과] 자연어 처리 [natural language processing] (한경 경제용어사전)
■ 컴퓨터가 인간의 언어를 알아들을 수 있게 만드는 학문분야. 인공지능의 하위 분야로, 일반적인 인공지능을 만들려던 1960년대의 시도가 실패한 후[1], 인간의 언어를 분석하고 해석하여 처리하는 인공지능이 세분화되면서 생긴 학문 분야. 흔히 우리가 아는 말하는 컴퓨터 및 인간과 대화하는 컴퓨터 관련 기술이 이 쪽에 속한다. 언어공학, 컴퓨터과학, 인공지능, 전산언어학(Computational Linguistics)의 연구 분야이며, 자연어를 컴퓨터로 해석하고, 의미를 분석하여 이해하고, 자동으로 생성하는 것 등에 관련된 분야다. 이 분야의 하위 분류로 정보 추출, 자동 교정, 대화 시스템, 기계 번역 등이 있다.
https://namu.wiki/w/%EC%9E%90%EC%97%B0%20%EC%96%B8%EC%96%B4%20%EC%B2%98%EB%A6%AC
자연 언어 처리 - 나무위키
Information Extraction. IE. 비정형의 문서로부터 정규화된 정보를 뽑아내는 기술, 크게 개체명 인식(NER)과 관계 추출(relation extraction)으로 나뉘어진다. 예를 들어 위키피디아 문서에서 사람, 회사 이름
namu.wiki
■ 자연어 처리(自然語處理) 또는 자연 언어 처리(自然言語處理)는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 모사 할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나다. 자연 언어 처리는 연구 대상이 언어 이기 때문에 당연하게도 언어 자체를 연구하는 언어학과 언어 현상의 내적 기재를 탐구하는 언어 인지 과학과 연관이 깊다. 구현을 위해 수학적 통계적 도구를 많이 활용하며 특히 기계학습 도구를 많이 사용하는 대표적인 분야이다. 정보검색, QA 시스템, 문서 자동 분류, 신문기사 클러스터링, 대화형 Agent 등 다양한 응용이 이루어지고 있다.
인공지능 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 인공지능(人工知能, 영어: artificial Intelligence, AI)은 인간의 학습능력, 추론능력, 지각능력, 논증능력, 자연언어의 이해능력 등을 인공적으로 구현한 컴퓨터 프로
ko.wikipedia.org
https://ko.wikipedia.org/wiki/%EC%9E%90%EC%97%B0%EC%96%B4_%EC%B2%98%EB%A6%AC
자연어 처리 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 자연어 처리(自然語處理) 또는 자연 언어 처리(自然言語處理)는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 모사 할 수 있도록 연구하고 이를 구현하
ko.wikipedia.org
□ 자연어 처리에 사용되는 기술
■ 개요
자연어 처리에는 자연어 분석, 자연어 이해, 자연어 생성 등의 기술이 사용된다.
■ 자연어 분석: 자연어 분석은 그 정도에 따라 형태소 분석(morphological analysis), 통사 분석(syntactic analysis), 의미 분석(semantic analysis) 및 화용 분석(pragmatic analysis)의 4 가지로 나눌 수 있다.
■ 자연어 이해: 자연어 이해는 컴퓨터가 자연어로 주어진 입력에 따라 동작하게 하는 기술이다.
■ 자연어 생성: 자연어 생성은 동영상이나 표의 내용 등을 사람이 이해할 수 있는 자연어로 변환하는 기술이다.
TTA정보통신용어사전
한국정보통신기술협회(TTA)는 정보통신 기술 발전과 타 분야와의 기술 융합에 따라 무수히 생성되는 정보통신용어를 해설하고 표준화하여, 전문가뿐만 아니라 비전문가들도 올바르게 활용할 수
word.tta.or.kr
□ 자연어 분석
■ 개요
자연언어의 분석 과정은 형태소분석 (Morphology Analysis) 통사분석 (Syntactic Analysis) 의미분석 (Semantic Analysis) 화용분석 (Pragmatic Analysis) 의 네 단계로 나눌 수 있다. 형태소 분석은 입력된 문자열을 분석하여 형태소라는 자연언어 분석을 위한 기본 단위로 분류하는 것이다. 이를 위해 형태소 분석기는 어휘사전 (lexicon) 을 바탕으로 입력 문자에 형태소 결합 규칙을 역으로 적용하여 형태소를 분석하고, 각 형태소가 가진 범주 (category) 정보를 어휘사전으로부터 추출하여 함께 출력한다. 즉, "친구였다" 라는 어절로부터 "친구 (명사) + 이 (서술격 조사) + 었 (선어말 어미, 과거) + 다 (어말 어미, 종결형)" 과 같은 결과를 만들어내는 것이 형태소 분석기의 역할이다. - (김영택, 1994)

■ 형태소 분석
→ 형태소 분석은 언어의 특성이나 맞춤법 등에 따라 난이도가 달라진다. 즉 영어는 형태소 분석이 매우 쉬우나, 한국어는 형태소적으로 복잡하므로 상대적으로 어렵다. 또한 한국어는 복합 명사 내의 명사를 붙여 쓸 수 있으므로 추가의 어려움이 있다. 일본어는 띄어쓰기를 하지 않으므로 형태소 분석에 또 다른 어려움이 있다. - (김영택, 1994)
→ 주어진 언어 문장에서 구조를 파악하고, 문장 분할, 분석, 추출, 원형 복원을 거쳐 의미를 갖는 최소 단위인 형태소(morphemes)를 발굴해 내는 과정. 자연 언어 문자열로부터 의미를 추출하기 위한 언어 분석의 첫 단계로서 특히 한국어, 일어처럼 어미와 조사 등 문법 형태소의 기능에 의해 단어의 통사적, 의미적 역할이 결정되는 교착어에서는 형태소 분석이 이후에 일어나는 구문 분석(syntax analysis)과 의미 분석(semantic analysis)에 미치는 영향이 크기 때문에 형태소 분석의 정확성이 아주 중요하다. - (한국정보통신기술협회)
→ 자연 언어 처리에서 말하는 형태소 분석이란 어떤 대상 어절을 최소의 의미 단위인 '형태소'로 분석하는 것을 의미한다. (형태소는 단어 그 자체가 될 수도 있고, 일반적으로는 단어보다 작은 단위이다.) 정보 검색 엔진에서 한국어의 색인어 추출에 많이 사용한다. 형태소 분석 단계에서 문제가 되는 부분은 미등록어, 오탈자, 띄어쓰기 오류 등에 의한 형태소 분석의 오류, 중의성이나 신조어 처리 등이 있는데, 이들은 형태소 분석에 치명적인 약점이라 할 수 있다. 복합 명사 분해도 형태소 분석의 어려운 문제 중 하나이다. 복합 명사란 하나 이상의 단어가 합쳐서 새로운 의미를 생성해 낸 단어로 '봄바람' 정보검색' '종합정보시스템' 등을 그 예로 들 수 있다. 이러한 단어는 한국어에서 띄어쓰기에 따른 형식도 불분명할 뿐만 아니라 다양한 복합 유형 등에 따라 의미의 통합이나 분해가 다양한 양상을 보이기 때문에 이들 형태소를 분석하는 것은 매우 어려운 문제이다. 기계적으로 복합명사를 처리하는 방식 중의 하나는, 음절 단위를 기반으로 하는 bi-gram이 있다. 예를 들어, '복합 명사'는 음절 단위로 '복합+명사', '복+합명사', '복합명+사' 의 세 가지 형태로 쪼갤 수 있고, 이 중 가장 적합한 분해 결과를 문서 내에서 출현하는 빈도 등의 추가 정보를 통해 선택하는 알고리즘이 있을 수 있다. 일반적으로, 다양하게 쪼개지는 분석 결과들 중에서 적합한 결과를 선택하기 위해, 테이블 파싱이라는 동적 프로그래밍 방법을 사용한다.
- 나는 → 나(대명사) + 는(조사)
- 나는 → 날(동사) + 는(관형형어미)
- (위키피디아)
■ 통사 분석(구문 분석)
→ 문장 속에 있는 형태소 혹은 단어들은 각자의 역할을 가지고 있다. 그리고 동시에 단순한 형태소나 단어를 조합한다고 해서 문장이 되는 것은 아니다. 통사 규칙 (syntactic rule) 은 형태소들이 결합하여 문장이나 구절을 만드는 규칙이다. 통사 분석은 통사 규칙에 따라서 문장 내에서 각 형태소들이 가지는 역할, 혹은 상호 관계를 분석하는 것이다.
"학생이 학교에 간다" 라는 문장이 통사적으로 옳으며, "학생" 이 문장의 주어가 됨을 분석하는 것이 통사 분석의 예이다. 그리고 "Love I you" 가 영어 문장으로 부적합한 이유는 통사 규칙에 맞지 않기 때문이며, 통사 분석에서는 이러한 사실도 밝혀낼 수 있어야 한다. -(김영택, 1994)
→ 컴퓨터 분야에서는 ‘구문 해석’이라 하나 언어학에서는 ‘통사 분석’이라 함.
※ 통사: 생각이나 감정을 말과 글로 표현할 때 완결된 내용을 나타내는 최소의 단위. 주어와 서술어를 갖추고 있는 것이 원칙이나 때로 이런 것이 생략될 수도 있다. 글의 경우, 문장의 끝에 ‘.’, ‘?’, ‘!’ 따위의 마침표를 찍는다. ‘철수는 몇 살이니?’, ‘세 살.’, ‘정말?’ 따위이다. - (한국정보통신기술협회)
→ 언어학에서 구문 분석(構文分析, 문화어: 구문해석, 문장해석) 또는 '파싱'은 문장을 그것을 이루고 있는 구성 성분으로 분해하고 그들 사이의 위계 관계를 분석하여 문장의 구조를 결정하는 것을 말한다. - (위키백과)
→ 문법을 이용하여 문장의 구조를 찾아내는 process. 문장의 구문 구조는 Tree 형태로 표현할 수 있다. 즉, 몇 개의 형태소들이 모여서 구문 요소(구: phrase)를 이루고, 그 구문 요소들간의 결합구조를 Tree형태로써 구문 구조를 이루게 된다. - (참조 pdf 파일)

■ 의미 분석
→ 의미 분석은 통사 분석 결과에 해석을 가하여 문장이 가진 의미를 분석해내는 작업이다. 문장이 가진 의미는, 문장을 구성하는 각 형태소가 가진 의미가 합성되는 단순한 유형에서부터, 은유와 같은 보다 고도의 분석을 요하는 유형까지 다양하다. 의미 분석을 위해서는 각 어휘 혹은 형태소에 의미 표지를 부여하고, 하위 범주화와 같은 정보를 이용하여 부분의 의미를 통합하여 전체 의미를 구성하는 방법을 이용하는 것이 자연언어처리에서 일반적으로 사용되는 기법이다.
"돌이 걸어간다" 라는 문장은 통사적으로는 옳다. 왜냐하면 명사 "돌" 을 명사 "학생" 으로 치환한 "학생이 걸어간다" 가 올바른 문장이기 때문이다. 그러나 "걸어간다" 라는 동사는 "걸을 수 있는 어떤 것" 을 주어로 하위 범주화 하며, "돌" 은 살아있는 물체가 아니므로 하위 범주화 규칙에 어긋난다. 따라서 위의 문장은 의미적으로 틀렸다. 그런데 가끔은 "돌이 걸어간다" 가 옳은 문장으로 간주되어야 하는 경우도 있을 수 있다. "걸어가는 사람" 의 별명이 "돌" 일 수도 있고 돌이 의인화된 문학 작품으 한 구절일 수도 있기 때문이다. 따라서 자연 언어의 의미 분석은 간단히 해결될 수 있는 문제가 아니며, 많은 경우 자연언어 시스템이 처리하는 문제의 영역 (domain) 에 따라 그 처리 방법이 좌우되기도 한다. -(김영택, 1994)
→ 자연 언어 이해 기법의 하나로, 문장의 의미에 근거해서 그 문장을 해석하는 방법. 여러 의미 분석 방법과 다양한 유형의 문법을 이용하는데, 이들은 문장이 어떻게 구성되었는가를 나타내 주는 규칙들로 구성된 일종의 형식 시스템이다. - (한국정보통신기술협회)
→ 통사 분석 결과에 해석을 가하여 문장이 가진 의미를 분석. 형태소가 가진 의미를 표현하는 지식 표현 기법이 요구됨. 통사적으로 옳으나 의미적으로 틀린 문장이 있을 수 있음.
– 사람이 사과를 먹는다. (o)
– 사람이 비행기를 먹는다. (x)
– 비행기가 사과를 먹는다. (x)

- (참조 pdf 파일)
→ 구문분석기 (syntactic analyzer)에 의해 생성된 구조들에 의미 (meaning) 가 부여된다. 이 단계에서는 각 단어가 지식베이스에서의 적절한 개체로 mapping 되어서, 각 단어의 의미가 서로 결합하는 방법으로 정확한 구조를 만들어야 한다. 의미구조를 표현하는 대표적인 문법에는 의미망 (Semantic Network), 격문법 (Case Grammar), 몬태규 문법 (Montague Grammar), 개념의존 (Conceptual Dependency) 가 있다.
의미해석의 자연어 처리기술은 현재 미해결된 문제가 매우 많다. 특히 컴퓨터 내부에서 의미를 어떤 형식으로 표현하여 어떻게 조작하는가에 대한 문제가 많이 남아 있는데 비록 의미의 형식을 정했다 하더라도 구문해석 결과에서 어떻게 그 형식의 의미를 추출해야 하는가가 문제이다. 또한 구문해석에서 발생한 문제를 제한시키기 위하여 의미해석 기술이 사용되는 것이다. 예를 보자.
[문장1] 소년은 냇가에서 수영하고 있는 소녀를 보았다.
[문장2] 소년은 다리 위에서 수영하고 잇는 소녀를 보았다.
위의 문장에서 '냇가에서'와 '다리 위에서'가 어떠한 구문구조로 해석되어야 할 것인가는 구문적으로는 해결이 되지 못하고 의미관계를 분석하는 의미해석 단계에서 비로소 결정될 수 있음을 알 수 있다. 이외에 동음이의어 및 문법적 다기능어가 있는데 의미해석 기술에서도 현재 해결이 어려운 경우가 많이 발생한다. 따라서 현재의 처리기술로서는 문맥 해석 기술로 처리하거나 대상에 밀착된 표현을 사용함으로써 인간이 오히려 문제를 줄이는 방법을 사용하고 있다.
한국어 문장의 경우는 다음과 같이 낱말 사이의 수식관계가 문장 구조의 기본을 이룬다.
나는 오늘 컴퓨터 책을 샀다.
'나는' '오늘' '책을' 이 모두 '샀다' 에 걸리고, '컴퓨터' 가 '책을' 에 걸린다.한국어가 영문과 다른 또 한 가지는 어순이 비교적 자유롭다는 것이다. 예를 들어, 앞의 문장은 다음과 같이 바꿔써도 뜻이 완전히 같다.
오늘 컴퓨터 책을 나는 샀다.
이러한 특징을 가진 한국어의 의미해석에는, 동사를 중심으로 하는 격문법이 가장 바람직하다. 영문의 격을 결정하는 데에는 어순이 큰 영향을 미치지만, 한국어 문장의 격은 조사가 결정적인 역할을 한다 - (최기선, 1992)
■ 화용 분석
→ 화용 분석은 문장이 실세계와 가지는 연관관계를 분석한다. 예를들어, "네 뒤에 벼랑이 있는지 알고 있니?" 라는 문장은 단순히 벼랑의 존재를 알려주는 역할 뿐 아니라 벼랑이 있으니 조심하라는 경고의 의미도 포함한다. 그리고 우리말에서 높임말은 주어나 대화의 상대가 글 쓰는 사람이나 화자 보다 높은 위치에 있을 때 사용된다. 이와 같은 화용 분석은 특히 자연언어에 대한 질의어를 분석하거나 사용자 인터페이스를 구축하기 위해서는 매우 중요하다. 화용 분석은 실세계 지식, 상식 등과 같은 지식을 바탕으로 화자와 청자의 대화 의도를 분석하는 것이 요구된다. -(김영택, 1994)
→ 말하는 이, 듣는 이, 시간, 장소 따위로 구성되는 맥락과 관련하여 문장의 의미를 체계적으로 분석하는 것 -(한국정보통신기술협회)
참조
https://cs.kangwon.ac.kr/~leeck/NLP/01_intro.pdf
http://www.aistudy.co.kr/linguistics/natural/semantic_analysis.htm
의미 분석 : Semantic Analysis
Semantic Analysis ........... 구문분석기 (syntactic analyzer) 에 의해 생성된 구조들에 의미 (meaning) 가 부여된다. 문장 "Colorless green ideas sleep furiously" (Noam Chomsky, 1957) 이 주어진다면 누구나 의미가 비
www.aistudy.co.kr
http://www.aistudy.co.kr/linguistics/natural/concept_kim.htm
자연언어처리의 개념 : 김영택
agreement : [number : singular]
www.aistudy.co.kr
□ 자연어 이해
■ 자연어 이해란
→ 자연어 이해는 컴퓨터가 자연어로 주어진 입력에 따라 동작하게 하는 기술이다. -(한국정보통신기술협회)
→ 자연어 이해 (자연어 understanding) 란 한 가지 표현방법에서 다른 표현 방법으로 변환시켜 자연어의 숨은 뜻을 정확히 알아내는 것을 말하는 것으로서, 자연어를 완벽하게 이해한다는 것은 충분한 사전지식이 없으면 결코 쉬운 일이 아니다.
예를 들면, Kim: "What do you like tonight, LG or Hai-Tai?" 즉 김 X X 가 "오늘밤 럭키금성 혹은 해태 중 어느 것을 좋아하는가 : 라고 질문을 하였다. 이때 만약 우리가 이러한 질문을 완전히 이해하였다면 오늘 저녁 TV에서 중계하는 야구게임에서 럭키금성과 해태가 경기를 하는데 어느 팀을 좋아하는가를 질문하는 것임을 알아야 한다. 또한, 질의 응답 지원을 위한 전문가 시스템상에서 '가능한 빨리 알고 싶다'라고 말하였을 시, 이러한 시스템을 완벽하게 이해하였다면 가능한 빨리 알고 싶어하는 질의에 대한 해 (solution) 를 찾게 될 것이다.
Rich의 항공기 예약 시스템에서 자연어 이해를 살펴보면 다음과 같다. 항공기 예약 시스템에서, "I want to go to N.Y. as soon as possible." 라고 말한다면 이러한 시스템에서는 N.Y. 에 가는 첫 비행기를 찾아내라는 것으로 이해를 하게 될 것이다. 그러나 만약에 당신의 가족이 N.Y. 에 살고 있다는 것을 아는 여자친구에게 동일한 이야기를 하였다면, 그 여자친구는 당신의 가족에 어떤 문제가 생겼다는 의미로 이해를 할 수도 있기 때문에 자연어를 완벽하게 이해한다는 것은 결코 쉬운 일이 아니다.
또한, 영어나 우리말도 동일한 단어가 여러 개의 의미를 갖는 것이 많다. 예를 들면 영어의 'diamond' 는 보석이 될 수 있고, 야구장의 다이아몬드를 의미할 수도 있으며, 우리말의 '배'를 보면 바다나 강에서의 교통 수단인 배가 될 수 있고, 과일로서 먹는 배가 될 수 있으며, 인간 및 동물 등의 신체부분인 배의 의미가 될 수 있으므로 더욱 자연어를 완벽히 이해한다는 것은 쉬운 일이 아님을 강조한다. - (김화수, 1993)
→ NLU란 자연어 표현을 기계가 이해할 수 있는 다른 표현으로 변환시키는 것을 뜻한다. 형태소 분석이나 구문 분석과 같은 자연어 처리 (NLP)와 혼용해서 사용되는 경우가 많으나 자연어 이해 (NLU)가 더 큰 개념으로 단순히 단어나 문장의 형태를 기계가 인식하도록 하는 것이 아닌, 의미를 인식하도록 하는 것을 의미한다. 자연어 이해 (NLU) 기능의 예를 들자면 "문장의 의도 분류" , "서로 다른 언어간 번역 문장 생성", 자연어 질문에 대한 답변 추출 등이 있다.
NLU (자연어이해) 라는 기술이 등장한 취지는 기계의 언어가 아닌, 사람이 평소 쓰는 자연스러운 표현 그대로 제공해도 기계가 알아들을 수 있도록 하는 데 있다. 영화 "스타워즈" 의 C-3PO나, R2D2, "아이언맨"의 자비스 같은 로봇 비서를 예로 들 수 있다. 우리 주변 가까이에서 찾아볼 수 있는 NLU (자연어이해)의 예로는 "애플 - Siri" , "삼성 - 빅스비" 등이 있다. 우리는 일상 표현으로 스마트폰과 직접 대화하면서 명령을 내리지 따로 코딩을 타이핑해 명령을 내리지는 않는다. 물론 아직 사람과 대화하는 것 같은 자연스러운 느낌을 얻기는 부족하고 기계가 처리할 수 있는 상황의 종류도 한계가 있지만 언젠가는 스마트폰 너머에 사람이 있는 것 같은 착각이 들 정도로 자연스러운 인공지능이 나올 것은 분명한 사실이다.
딥러닝 (Deep Learning)기술의 발전 덕분에 전통적인 통계 및 룰 기반의 자연어 이해 (NLU)기법이나 머신러닝(Machine Learning)방식의 자연어 이해 (NLU) 기법의 한계를 해결할 수 있게 됐다. 지난 수십년 간의 전통적인 자연어 이해 (NLU)방식은 사람이 직접 추출한 특징에 강하게 의존했다고 볼 수 있다. 이러한 특징들은 추출하는 데 시간이 많이 소요되고, 여러 다양한 경우에서 불완전하다는 것에 있었다. 그러나 최근 수십년 밀집된 벡터 표상에 기반한 인공신경망(ANN)이 다양한 자연어처리(NLP)에서 우수한 성능을 보여준 바 있다. 이러한 트랜드는 '워드 임베딩'과 '딥러닝 기술'의 성공에 힘입은 것이라 할 수 있다. 딥러닝 특징들을 자동으로 추출하고 표현할 수 있게 하는데 이러한 장점으로 인해 딥러닝 기반의 자연어 이해(NLU)기법 연구가 활발해졌다. - (LG CNS)
■ 전통적 방식(룰 기반 또는 머신러닝 기반)의 한계
룰 기반의 NLU 방식은 사람이 직접 추출한 Feature에 의존하는 것으로, Feature를 수작업으로 추출하는 데 시간 많이 소요되며 예외 처리 등에 취약합니다. 또한, 처리 대상 문장이나 문서가 길어질수록 정확도가 하락하는 경향이 있고, 처리 가능한 문서도 정형화된 텍스트에 한정된다는 특징이 있습니다.
규칙 기반의 수작업 특성상 처음 등장하는 신조어, 오타 등에 취약한 단점이 있는데요. 머신러닝 기반의 NLU 기법은 기계가 자동으로 모델을 학습하면서 룰 기반 방식의 공수를 많이 덜 수 있었습니다. 하지만 이 역시 모델의 구조(모델이 단순한 1차 함수인지, 더 고차원인지, 혹은 로지스틱 곡선을 그리는지 등)를 미리 지정해줘야 하는 등 작업자의 개입이 필요했습니다.
■ 딥러닝 방식의 개선
딥러닝 기반의 NLU 방식은 데이터로부터 Feature를 자동으로 학습하는 방식입니다. 기존보다 폭넓은 문맥 정보 처리가 가능하고, 사진, 음성 등과 같이 다른 분야의 모델들과 연결한 Multi-modal 모델 구축이 쉬워진 장점이 있습니다. 예를 들어 이미지를 Input으로 받아서 간략히 설명하는 캡션을 생성하는 모델이 있습니다.
기존에 학습하지 않은 신조어나 오타에 robust 한 처리 기술이 있어서 룰 기반 방식의 한계를 보완할 수 있습니다. 또한, 모델의 구조를 미리 지정하지 않고 학습을 통해 모델을 만들어서 작업자의 개입이 최소화되며, 복잡하고 깊은 구조를 만들 수 있어 기존 방식보다 정확도가 높습니다.
■ NLU를 사용하는 기술
(1) 워드 임베딩 기술
워드 임베딩 기술은 단어나 형태소를 벡터화하는 기술이다. 단어를 벡터로 만들었다면 문장이나 문서를 매트릭스로 변환하는 작업이 가능해진다. 이렇게 되면 비로소 문장 감성 분류나, 기계 번역 등과 같은 task를 딥러닝 모델로 학습할 수 있게 된다.
(2) MRC 기술 및 대화 모델
기계를 조금 더 사람답게 만드는 기술이다. MRC는 질의 응답 기술로, 사용자가 어떤 질문을 했을 때 기계는 자신이 학습했던 내용 중에서 적절한 답변을 알아서 찾아 제공해주는 것이다. 이 기술을 잘 연마한 로봇은 퀴즈쇼에서 우승할 수도 있다고 한다. 대화 모델은 위와 같은 기술들을 사람처럼 자연스러운 대화가 이어질 수 있도록 하는 기술이다.
■ 다양한 언어 모델
언어 모델이 사람의 말을 얼마나 잘 이해하는지는 어떻게 평가해볼 수 있을까요? 앞에서 설명한 대로, 언어를 이해한다는 행위는 구체적으로 정의하기도, 검증하기도 어렵습니다. 이에 전문가들은 제시된 것처럼 정답이 명확하게 주어진 여러 문제를 고루 잘 푸는 모델을 기준으로 삼았습니다. 다양한 과제를 잘 수행한다면 나중에 비슷한 종류의 새로운 데이터에서도 잘 작동한다고 가정했습니다.
언어 모델의 성능 평가에는 GLUE와 SuperGLUE라는 벤치마크가 주로 활용됩니다. 기존 9가지 라벨링 데이터셋을 모아 만든 GLUE는 다양한 과제에서 딥러닝 모델이 좋은 성능을 내는지를 살펴보는 데 방점을 둡니다. 2018년 탄생한 사전학습된 딥러닝 기반 언어 모델(ELMo, GPT-1, BERT) 모두 GLUE 벤치마크에서 당시 최고의 성능을 달성했습니다. 그중에서도 BERT를 업그레이드한 버전인 MT-DNN[5]와 RoBERTa는 GLUE 벤치마크를 기준으로 인간보다 뛰어난 성능을 내보이기도 했죠. GLUE보다 ‘더 어려운’ 자연어이해 과제를 모은 벤치마크가 SuperGLUE입니다. 8가지 데이터셋으로 구성된 SuperGLUE도 GLUE와 마찬가지로 다양한 NLU 문제를 해결할 수 있는지를 평가하는 데 주안을 두고 있습니다.
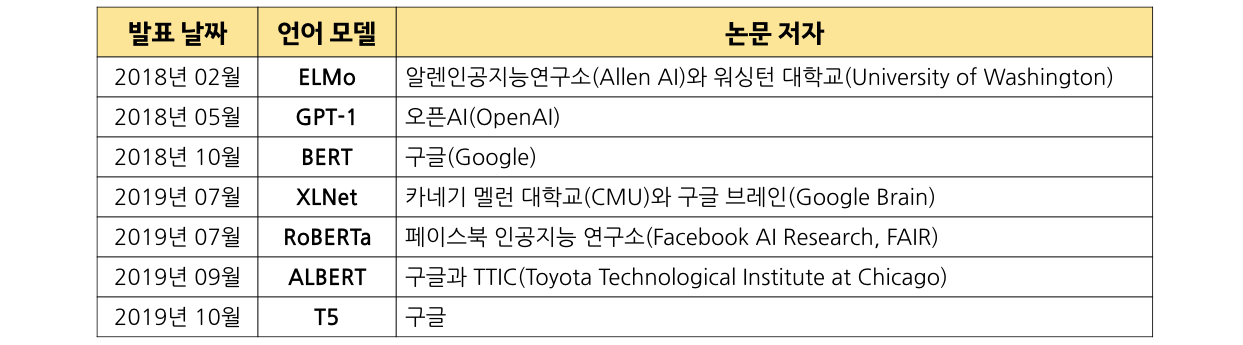
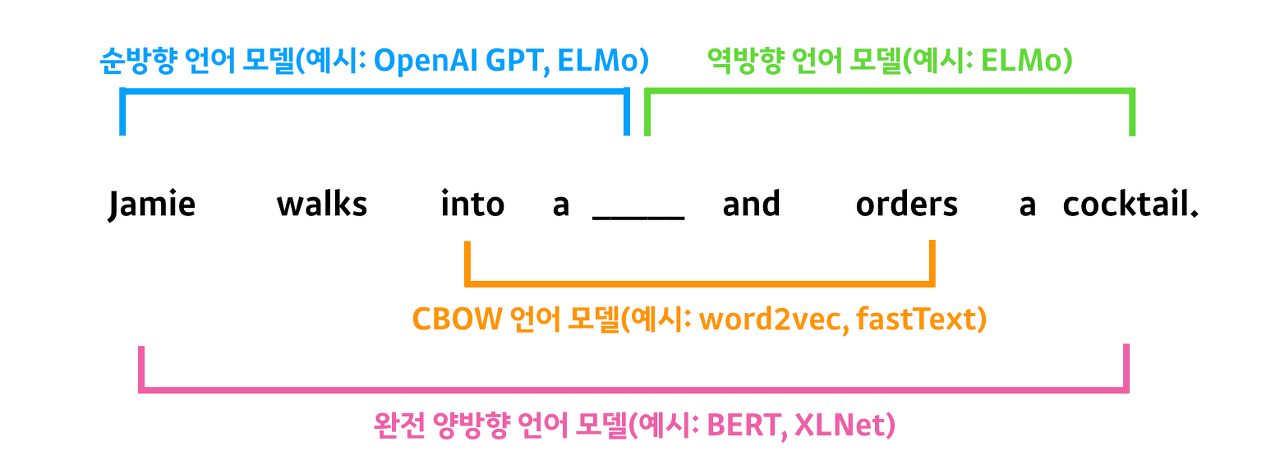
ELMo는 방대한 텍스트 데이터를 (사전) 훈련받은 대규모 언어 모델이 다양한 NLU 과제에서 최고의 성능을 낼 수 있음을 최초로 증명했습니다. ELMo는 양방향 LSTM 아키텍처를 이용해 주어진 단어 시퀀스(sequence) 다음에 오는 단어(순방향) 또는 앞에 오는 단어(역방향)를 예측합니다. 그 결과, ELMo는 6가지 주요 NLU 벤치마크에서 모두 최고의 성능을 갱신하는 데 성공합니다.
.
.
.
참조
http://www.aistudy.co.kr/linguistics/natural/nlp_kim.htm
http://www.aistudy.co.kr/linguistics/natural/nlp_kim.htm
CLAUSES unik([ ],[ ]). unik([H|T],L) :- member(H,T),!,unik(T,L). unik([H|T],[H|L]) :- unik(T,L). member(X,[X|_]). member(X.[_|L]) :- member(X,L). write_list(_,[ ]). write_list(4,[H|T]) :-!, write(H), nl, wri
www.aistudy.co.kr
https://www.kakaobrain.com/blog/118
2018-2020 NLU 연구 동향을 소개합니다 - 카카오브레인
지난 2018년을 기점으로 폭발적으로 성장한 사전학습된 언어 모델과 최신 자연어이해(NLU) 과제의 한계, 올해의 NLU 연구 트렌드에 대한 내용을 다뤄보고자 합니다. 카카오브레인에서 자연어처리
www.kakaobrain.com
https://woongsin94.tistory.com/341
자연어 이해(Natural Language Understanding, NLU)
자연어 이해 , NLU NLU란 자연어 표현을 기계가 이해할 수 있는 다른 표현으로 변환시키는 것을 뜻한다. 형태소 분석이나 구문 분석과 같은 자연어 처리 (NLP)와 혼용해서 사용되는 경우가 많으나
woongsin94.tistory.com
인간의 언어를 이해하는 " 자연어 이해 " NLU
컴퓨터와 같은 기계에 우리가 원하고자 하는 바를 수행하도록 하려면, 우리는 기계가 알아들을 수 있는 표...
blog.naver.com
인간의 언어를 이해하는 기계, NLU
컴퓨터와 같은 기계에 우리가 원하고자 하는 바를 수행하도록 하려면, 우리는 기계가 알아들을 수 있는 표현으로 명령문을 내려야 합니다. 필요한 문장을 출력하게 할 때도 print 명령문을 이용
blog.lgcns.com
□ 자연어 생성
■ 자연어 생성이란
→ 자연어 생성은 동영상이나 표의 내용 등을 사람이 이해할 수 있는 자연어로 변환하는 기술이다. -(한국정보통신기술협회)
■ 언어 모델이란?
언어 모델(Language Model)은 짧게 요약하면 문장. 즉, 단어의 시퀀스의 확률을 예측하는 모델이다. 언어 모델은 자연어 생성(Natural Language Generation)의 기반이 된다. 기본적으로 자연어 생성과 관련된 건 모두 언어 모델과 관련이 있다. 음성 인식, 기계 번역, OCR, 검색어 자동 완성 등과 같은 것은 전부 언어 모델을 통해 이루어진다.
언어 모델을 만드는 방법은 크게 통계를 이용한 방법과 인공 신경망을 이용한 방법으로 구분할 수 있다. 최근 자연어 처리에서 언어 모델에 대한 이야기를 빼놓을 수 없는데, 최근 핫한 딥러닝 자연어 처리의 기술인 GPT나 BERT가 전부 언어 모델의 개념을 사용하여 만들어졌기 때문이다. 인공 신경망의 일종인 RNN, LSTM 등을 통해 언어 모델을 만들어 볼 수 있다. 또한 seq2seq를 통해 기계 번역기를 만들어볼텐데 이 또한 결국 언어 모델이다.
■ 언어 모델(Language Model)이 하는 일
언어 모델이 하는 일은 간단하게 요약하자면 문장의 확률을 예측하는 일이다. 그런데, 문장의 확률을 예측하기 위해서는 우선 이전의 단어들이 주어졌을 때 다음 단어가 나올 확률을 예측해야한다. 자연어 처리로 유명한 스탠포드 대학교에서는 언어 모델을 문법(Grammar)이라고 비유하기도 한다. 언어 모델이 단어들의 조합이 얼마나 적절한지, 또는 해당 문장이 얼마나 적합한지를 알려주는 일을 하기 때문이다.
■ 최신 언어 모델
최근 인공지능(AI) 자연어 처리(NLP)에서 가장 화제가 되고 있는 플랫폼으로는 구글의 양방향 언어모델 버트(Bert), OpenAI의 단방향 언어모델 GPT-2, 기계신경망 번역(Transformer) 모델 등을 꼽을 수 있다.
이 가운데 지난 1일(현지시간) OpenAI가 새로운 강력한 언어 모델 'GPT-3(Generative Pre-Training 3)'를 아카이브(arXiv)를 통해 공개했다. 이는 지난해 초에 공개한 소설 쓰는 인공지능 'GPT-2' 보다 훨씬 더 크고 혁신적인 버전으로 진화된 모델이다.
이 모델은 4990억개 데이터셋 중에서 가중치 샘플링해서 3000억(300B)개로 구성된 데이터셋으로 사전 학습을 받았으며, 1750억개(175Billion) 매개 변수로 딥러닝의 한계까지 추진돼 미세 조정없이 여러 자연어 처리 벤치마크에서 최첨단 성능을 달성했다. 발표된 내용이라면 단 몇 개 키워드만 넣으면 작문을 작성해주는 혁신적인 AI 언어생성 모델이자 알고리즘인 것이다.
OpenAI 연구팀(31명의 공동 저자)은 무려 74페이지의 연구 논문(Language Models are Few-Shot Learners)을 통해 이 모델에 대한 여러 기능과 실험에 대해 설명했다. 연구원의 목표는 미세 조정이 거의 없거나 전혀 없는 다양한 작업에서 잘 수행되는 NLP 시스템을 구현하는 것을 목표로 하고 있으며, 모델은 자체 감독학습(self-supervised learning)을 사용하여 공통 크롤링 데이터 세트(보기) 및 영어 위키 백과를 포함한 다양한 데이터 세트를 적용했다.
특히, 뉴스 기사 생성 작업에서 모델을 평가하기 위해 연구팀은 크라우드 소싱 플랫폼인 아마존 메커니컬 터크(Amazon Mechanical Turk)를 사용했다. GPT-3는 인간 평가자가 인간이 작성한 기사와 구별하기 어려운 뉴스 기사 샘플을 생성할 수 있다고 한다.
모델은 트랜스포머(Transformer), 어텐션(Attention) 등의 표준개념과 일반적인 커먼 크롤(Common Crawl), 위키피디아(Wikipedia), 도서 및 일부 추가 데이터 소스를 사용하여 빌드 된다. 다양한 작업에 GPT-3 모델을 사용하기 위해 그라디언트(Gradient) / 매개 변수 업데이트(미세 조정)를 수행 할 필요가 없다. 자연어를 사용하여 모델과 상호 작용하거나 수행하려는 작업의 예를 제공하면 모델이 수행할 수 있다.
작업 별 모델 아키텍처가 필요하지 않을 뿐만 아니라 대규모 사용자 지정 작업 별 데이터 집합이 필요하지 않다는 개념은 최첨단 NLP의 접근성을 높이는 방향으로 나아가는 큰 단계로 GPT-3은 단어 예측, 상식 추론과 같은 많은 NLP 작업에서 뛰어난 성능을 제공을 제공한다.
한편, OpenAI는 훈련된 모델 또는 전체 코드는 공개하지 않았지만, 모델에 의해 생성된 텍스트 샘플 모음뿐만 아니라 일부 테스트 데이터 세트를 포함하는 내용은 깃허브(다운)에 공개 했으며, 관련 연구 논문(Language Models are Few-Shot Learners)은 지난 1일 아카이브(다운)에 공개됐다. 이제, 기자도 곧 AI로 교체될 날이 머지않은 것 같다. 인공지능 자언어 처리가 어떻게 진화할 것인지 또 그 영향은 우리 모두에게 어떻게 파급될지 지켜보는 것이 흥미로울 것으로 보인다.

참조
자연어처리(NLP) 6일차 (언어 모델)
19.06.08
omicro03.medium.com
http://www.aitimes.kr/news/articleView.html?idxno=13117
인공지능(AI) 언어모델 ‘BERT(버트)'는 무엇인가 - 인공지능신문
지난해 11월, 구글이 공개한 인공지능(AI) 언어모델 ‘BERT(이하 버트, Bidirectional Encoder Representations from Transformers)’는 일부 성능 평가에서 인간보다 더 높은 정확도를 보이며 2018년 말 현재, ...
www.aitimes.kr
https://www.aitimes.kr/news/articleView.html?idxno=16599
[이슈] OpenAI, 혁신적인 AI 자연어처리(NLP) 모델 'GPT-3' 공개 - 인공지능신문
최근 인공지능(AI) 자연어 처리(NLP)에서 가장 화제가 되고 있는 플랫폼으로는 구글의 양방향 언어모델 버트(Bert), OpenAI의 단방향 언어모델 GPT-2, 기계신경망 번역(Transformer) 모델 등을 꼽을 수 있다
www.aitimes.kr
□ 챗봇이란
■'채팅하는 로봇', 즉, 채팅봇이라는 용어의 약자
■사용자를 대화상대로 텍스트나 음성기반의 대화를 수행하는 소프트웨어로, 고객서비스나 정보수집 용도로 활용되고 있다. 채터봇(Chatterbot)으로도 불리우며, 인공지능 비서(Artificial Assitance)와 혼용되어 사용되고 있다. 대표적으로는 구글 어시스턴트(Assistant), 애플 시리(Siri), 삼성 빅스비(Bixby) 등이 있다.
[네이버 지식백과] 챗봇 [Chat Bot] (시사경제용어사전, 2017. 11., 기획재정부)
■정해진 응답 규칙을 바탕으로 메신저를 통해 사용자와 대답할 수 있도록 구현된 시스템이다. 홈쇼핑, 인터넷 쇼핑몰, 보험사, 은행, 음식 배달, 숙박 예약 등에서 소비자의 질문에 대답해 주거나 기존 소비자의 성향을 바탕으로 적합한 상품을 추천해 주는 역할로 활용된다.
[네이버 지식백과] 챗봇 (시사상식사전, pmg 지식엔진연구소)
■사람처럼 자연스러운 대화를 진행하기 위해 단어나 구(句)의 매칭만을 이용하는 단순한 챗봇부터 복잡하고 정교한 자연어 처리 기술을 적용한 챗봇까지 수준이 다양하다. 챗봇은 채터봇(chatterbot), 토크봇(talkbot) 등의 이름으로도 불린다.
[네이버 지식백과] 챗봇 [Chatbot] (IT용어사전, 한국정보통신기술협회)
■기업용 메신저에 채팅하듯 질문을 입력하면 인공지능(AI)이 빅데이터 분석을 바탕으로 일상언어로 사람과 대화를 하며 해답을 주는 대화형 메신저를 말한다.
페이스북의 페이스북 메신저, 텐센트의 위젯, 텔레그램의 텔레그래, 킥의 봇숍, 슬랙사의 슬랙, 네이버웍스모바일의 운앱, 이스트소프트의 팀업 등이 이에 해당된다.
기업 입장에서 챗봇을 도입하며 인건비를 아끼고 업무시간에 상관없이 서비스를 제공할 수 있다는 장점이 있다. 하지만 개인정보 유출 등 부작용의 발생 가능성도 존재한다.
챗봇은 크게 인공지능형과 시나리오형으로 나뉜다.
시나리오형은 미리 정해 놓은 단어에 따라 정해진 답을 내놓기 때문에 보안 위험이 그리 크지 않다.
인공지능형 챗봇은 복잡한 질문에도 응답할 수 있고 자기학습도 가능하다. 하지만 이용자의 입력 단어에 의도치 않게 행동해 개인정보 유출, 피싱, 해킹 같은 보안 위협에 취약한 것으로 평가된다.
[네이버 지식백과] 챗봇 [chatter robot] (한경 경제용어사전)
□ 챗봇 5가지 대표 유형/종류
■ 대화형 챗봇
대화형은 자연어처리를 기반으로 자연스럽게 대화가 가능한 챗봇입니다. 인공지능 기반으로 되어 있으며, 머신러닝 및 딥러닝을 기본으로 합니다. 어떤 문장으로 질문을 하면 답변을 전달합니다.
일반적인 형태는 말풍선이지만 발화한 의도에 따라서 특정 콘텐츠를 노출시켜주기도하고 다른 트리거를 발생(서비스를 실행)시키기도 합니다. 결과적으로 질문을 분석하여 답변을 주는 프로세스입니다. 우리가 흔히 매체들을 통해보는 인공지능 챗봇일 것입니다.
기본적으로 인공지능 기반이므로 엄청난 비정형 데이터 확보가 필요하고, 구축 과정의 난이도가 높으며, 기간이 상당히 많이 소요됩니다.
- 비용: 매우 높음
- 전문성: 매우 높음
- 시간: 매우 높음

■ 트리형(버튼) 챗봇
정해진 트리구조를 따라 답변을 얻는 형태입니다. 인공지능은 아닙니다. 객관식 문제를 푸는 것과 같다고 생각하면 됩니다. 최종 답변을 위한 경우의 수는 정해져 있습니다. 쉽게 구축이 가능하고, 고객 피드백을 통해 경우의 수를 늘려나갈 수 있습니다.
일반적으로 자주하는 질문의 서비스에 사용되는 유형입니다. 챗봇의 1세대에서 많이 썼던 방식이며, 소규모 업체나 제공해야할 정보의 구조화가 잘 되어 있다면 추천하는 방식입니다.
- 비용: 매우 낮음
- 전문성: 낮음
- 시간: 보통

■ 추천형 챗봇
표면적으로는 대화의 형태를 띄고 있지만, 답변을 제공하는 방식이 대화형 챗봇과 다릅니다. 인공지능 기반일수도 있고 아닐수도 있습니다. 질문을 던지면 대화 형태의 답변을 제공하는 것이 아니라 사전에 정의된 답변의 리스트를 알고리즘 결과의 우선순위별로 보여줍니다. 아니면 단순하게 검색 결과의 리스트 형태로 보여줄 수도 있습니다.
추천 답변 리스트가 1개라고 하면 대화형과 사실상 다를게 없습니다. 추천 답변을 리스트로 제공하면 고객은 선택해야하는 번거로움이 있지만 원하는 답변을 얻을 확율이 높습니다. 현실적으로 인공지능 답변의 경우 완벽하지 않을 수 있기 때문입니다. 추천형 챗봇의 경우 인공지는 챗봇, 즉, 대화형 챗봇으로 가기 위한 중간 과정으로도 사용합니다.
- 비용: 보통
- 전문성: 보통
- 시간: 많음
■ 시나리오형 챗봇
원하는 서비스 혹은 아웃풋 제공을 위하여 정해진 시나리오를 수행해주는 챗봇입니다. 최종 결과 전달을 위해서 고객에게 받아야하는 정보를 순서에 따라 받아줍니다.
단순하게 로그인이라고 하면 아이디를 묻고 데이터를 받고 유효성 체크를 하고 비밀번호를 묻고 데이터를 받고 유효성 체크를 합니다. 결과를 위한 과정은 정해져 있습니다. 이 챗봇의 경우 단계가 있기 때문에 고객 이탈율 분석을 통해서 고객 경험을 단계별로 향상시킬 수 있습니다.
제공해야 할 서비스 혹은 결과물이 정해져 있을때 많이 사용하는 유형의 챗봇입니다. 챗봇 유형 중 가장 투자대비 효과가 좋은 챗봇 유형으로 알려져 있습니다.
- 비용: 보통
- 전문성: 보통
- 시간: 보통

■ 결합형 챗봇
비즈니스 목적에 따라 위의 챗봇 유형들을 결합해서 설계가 가능합니다. 최근 출시되는 챗봇들은 각 비즈니스 혹는 서비스 목적에 따라 각 유형의 챗봇들을 결합하고 있습니다. 최종 목적은 동일합니다. 결과적으로 고객이 챗봇에서 모든 서비스를 완료하는 것입니다.
챗봇 기획 단계: 챗봇의 5가지 대표 유형/종류를 정하는 과정에 있어서 비용, 전문성, 시간은 어떻게 조합하느냐에 따라 다릅니다. 정답은 없으며, 비즈니스에 가장 최적이 무엇인지를 사전 준비 단계를 통하여 설정해야 합니다.
챗봇 기획 단계: 챗봇의 5가지 대표 유형/종류

□ 자연어 처리와 챗봇의 관계
■ 자연어 처리(NLP)의 하위 분야
정보검색
정보 추출
음성 인식
단어 분류
구문 분석
문장/문서 분류
감정 분석
의미역 결정
기계 번역
자동 대화 시스템(대화형 챗봇, 음성 비서)
■ 챗봇의 여러 형태 중 '대화형 챗봇'이 자연어처리와 관계 있다. (대화형 챗봇은 자연어처리를 기반으로 자연스럽게 대화가 가능한 챗봇이다.)
□ 자연어 처리 엔진
■ 자연어 처리 엔진
인공지능 엔진(프로그램)은 종류가 다양하다. 음성, 이미지, 자연어 등을 처리해주는 다양한 엔진이 존재한다. 자연어를 처리해주는 엔진을 자연어 처리 엔진이라고 한다.
■ 챗봇 빌더란

■ 챗봇 빌더의 종류
Watson의 Conversation, MS의 Luis, 카카오의 카카오I, 구글의 DialogFlow 등이 있다.
대화형 챗봇을 만들기 위해 자연어 처리 엔진을 별도로 만들 필요 없이, 빌더를 사용하면 된다.
■ 챗봇 빌더 구조(예시)

클릭 몇 번으로 ‘챗봇’ 만들 수 있다고?(feat. DAP Talk)
앞선 콘텐츠를 통해 언어 AI의 다양한 적용 사례를 살펴보았습니다. ● 챗봇부터 음성봇까지! '언어 AI'가 나타났다: https://blog.lgcns.com/2282 언어 AI의 대표 주자인 챗봇 서비스는 이제 비즈니스의
blog.lgcns.com
http://www.saltlux.com/ai/talkbot.do?menuNumber=1
톡봇 대화 엔진
솔트룩스의 톡봇은 딥러닝과 지식그래프, 추론 기술이 융합된 앙상블 심층 대화 엔진입니다. ...
www.saltlux.com
□ 챗봇 주요 용어
■ 인텐트(Intent, 의도)
입력 문장이 어떤 의도인지 분류하기 위한 기준이다. '날씨 질문 인텐트', '자전거 고장 접수 인텐트', '회사 정보 질문 인텐트' 등을 예로 들 수 있다.
사용자의 질문을 받으면, 학습한 문장을 바탕으로 가장 적절한 대화 의도를 찾고 대답한다. 학습 데이터를 기입하면, 자연어 처리 엔진이 학습을 하게 되고, 이후 비슷한 표현을 쓰면 같은 질문으로 분류한다.

■ 말문장(Utterance)
인텐트를 표현하기 위한 다양한 예시 문장들이다. 인공지능 학습에 필요한 데이터라고도 말할 수 있다. 동일한 의미의 다양한 문장을 대화 엔진에 입력하고 학습 시켜야 사용자 의도를 제대로 파악할 수 있다.

■ 엔티티(Entity)
사용자의 말이나 문장 속에서 원하는 정보를 추출하여 적절하게 대화를 이끌어 나갈 수 있도록 설정하는 단어군(키워드)이다. 예를 들어, '리니지 어때?' 라고 질문했을 때, 인텐트는 '게임 질문'이라고 한다면, '리니지'는 엔티티(Entity)이다.
엔티티를 활용하면 인텐트를 관리하기 편할 것이다.
예를 들면, NC소프트에는 리지니, 아이온, 블레이드 앤 소울 등의 게임이 있다. 이때 '리니지 질문', '아이온 질문', '블레이드 앤 소울 질문' 등으로 인텐트를 분류하지 않고, '게임 질문' 하나로 통합할 수 있다.
■ 시나리오(Scenario) = Dialog management
미리 설계된 대화의 흐름

■ 슬롯 채우기(Slot Filling)
몇 개의 정보를 알아내야 답을 줄 수 있을 때, 그 몇개의 정보(Slot)을 다 채워 넣는(Filling) 것으로, 모든 슬롯이 다 채워질 때까지 질문한다.

■ 스몰토크(Smalltalk)
일상적 대화. 사교적 커뮤니케이션을 위한 대화들이다.

■ 챗봇 구현 예시
